How to simplify QA by testing frontends in production
January 11, 2023 by Kim Loomis, Product Owner @ Fathym
In this article:
- Understand software testing
- Acknowledge the time, cost and effort related to using different environments
- Test front ends in production environment

What is Software Testing?
Software testing can be a dreaded job. If this is what you do at a company, you are that alleged “speed bump” on the way to product release or mass production.
Let’s face it – your job is to find problems or to try to break stuff. Either way, it means that you are finding stuff that wasn’t created correctly or has some loopholes and you’re reporting it back to the creators. You’re “the messenger” or the “harbinger of doom.” No one likes to be told that they did something wrong, and they certainly don’t care for the person telling them so.
However, without software testing, it would be a horrible ordeal if you did go forward to product release or mass production. You would be putting something out in the wild that did not work. So, testers should be welcomed on the team and Software Testing should be a required, vital part of the development process.

A long time ago, a relative of mine worked at a large U.S. manufacturing corporation that made typewriters (machines that pre-dated computers). Testing took place before the machines were put together to ensure that the right parts were provided as well as after assembly, testing to check for binding keys, print quality, advance of the ribbon, and the movement of the carriage. Can you imagine if you hit the “e” key and it really printed a “z”? Anarchy!
The same is true with software development. We talk with the stakeholders at length to ensure we have accurately captured the requirements of what they want built. We hold architectural planning meetings to ensure that we have a well-designed plan to go forward with development. After development, Software Testing takes a hold of the software and puts it through rigorous trials, checking out both the most-used behavior and the lesser-known edge cases. It is one of the last steps made to make sure that you are ready to go forward and have the best chance of success with a product that works as expected.
How most companies test software
Testing software is part of a typical software development cycle.
To get started, most companies create a whole new environment to use for testing. This includes software, hardware, and network infrastructure. This can be costly and time-consuming as companies try to set up an exact replica of production. But without setting up an exact replica, the companies can never be 100% certain that the software will work in production.

Imagine building another house so that you could test new items for your house (your production house – i.e., the one you live in). You want a new HVAC system? You put it in the test house and make sure it will work. Does it properly cool and warm the house? Does it work well for the size and design of the house? Once the bugs have been wrung out of it, only then do you implement into your production house.
It seems a little absurd to do that, right? And, time-consuming. And you have two houses to maintain! That’s so expensive! And probably too expensive for almost anyone to do. The same is true in software. It is expensive to have a test environment that completely mirrors production.
With that in mind, organizations turn to testing on a small scale. They have a scaled down environment.

Instead of a million records, it has a few thousand. Maybe not all the services are turned on or turned up as in production. It’s a means to get a production-like environment on a small budget. And a much more easily managed environment, too, as it does not have all the same resources as production.
So, organizations have two alternatives. One, make an exact duplicate of production. That is expensive financially and from a management standpoint. Two, make a scaled-down representation of production. However, it may not be suitable for all testing and some things may get missed in the testing process. The organization runs the risk of putting out a buggy release.
Testing in production
Well, neither of those alternatives sound palatable. They are either spendy or inadequate. So, what else is there?
What about production? Can testing be done there?
To be honest, the rule of thumb is usually, “Don’t test in production!”
You don’t want your real users to be guinea pigs for new features or changes to existing functionality. You don’t want your well-running production application to suddenly be ladened with something new, just out of development. This is a poor practice.
Testing in production, though, sounds really alluring. Sounds easy and cost effective - nothing to set up, just use what you already have. You’d be testing with other production functionality and services. You’d be testing with production users and production data.
But…
And that’s a big ‘But’…
You could introduce problems into production and foul up workflows and processes. You could take down production altogether and be offline for an indeterminate amount of time. You could create a poor UI/UX experience for the users – users expect the product to work and when it doesn’t, it causes a real ripple effect. Users can get frustrated or angry that the software doesn’t work.
And worse, it will make them think the software is not trustworthy even when the wrongs are righted. You will have lost users’ trust. When users leave your product, you lose market share. That market share gets gobbled up by competitors.
Therefore, testing in production can be harrowing externally.
Internally, you could create a scenario where it is difficult to roll back. This could cause lots of rework, additional effort, and time by your development team to get the software back to working order. The development team may get frustrated or angry that they are having to fix things that worked. They could fix things and in the process of doing so, introduce new bugs. The developers could also become burnt out working more or longer hours.
And worst of all, a buggy release does not move your organization forward. No progress is being made.
Fathym Breaks the Rules
I’m going to say it right now, we test in production.
I will caveat that – Fathym tests front end changes in production on a QA path. Backend changes are still best to test in a separate environment, away from production. Front ends can change regularly as companies continuously work to improve interactions with customers by making small improvements and trying new ideas.
So. We. Test. Front Ends. In. Production.
I can sense the shocked faces. The cringing for our terrible practice. Perhaps even some praying for our wicked sacrilege.
But I also sense curiosity.
How does Fathym do that? And why does Fathym choose (willingly) to do that?
An Analogy
First, let’s look at this in a different way and give it more perspective.

Testing software in production is like taking a patient with a contagious disease to the main city hospital. The patient needs the care the hospital can provide. But you don’t want the disease the patient has to infect others in the hospital.
Traditionally, there are two options.
There is another hospital that is just for contagious disease patients. The hospital is an exact replica of the main city hospital. Same operations, same level of staffing, equipment and so on. While the patient may get an excellent level of care, that’s super expensive to have two hospitals. And likely, the hospital will never be fully utilized as the odds are that most sick people are able to go to the main hospital and don’t need this specialized center. Consequently, the cost per patient is extraordinary.
The other option is to have scaled-down operations somewhere offsite on the main city hospital’s campus. It’s a makeshift tent, with limited operations, personnel, and equipment. That’s probably not going to serve the patient very well. The patient may take a lot longer to get well. With so-so operations, the patient may infect others. Without the highest-level of care, the patient may never get well and die.
The solution is taking the patient into a “quarantined” part of the main city hospital, not the normal, everyday operational area. The patient takes advantage of all the things that are used by the hospital production but is just not in mainstream production themself. Once the patient gets well enough (i.e., passes the tests) to move to a desegrated part of the hospital, the patient becomes part of the normal production operations of the hospital. This is cost efficient, spreading the cost of staff, building, equipment and operations over a larger patient base.
The Engine
Let’s open the hood and see how testing frontends in production is done.
“We mimic what we have out in production within production,” says Matt Jackson, Fathym’s Quality Assurance guru, under which, software testing falls.
Are you still following?
Within the Fathym enterprise, there is a Production project and in there is a QA application. And within that application, there are several different routes configured. The routes represent several different large features of the Fathym technology portfolio. This includes our Create Project Wizard, Social Dashboard, IoT Ensemble, Habistack and many others.
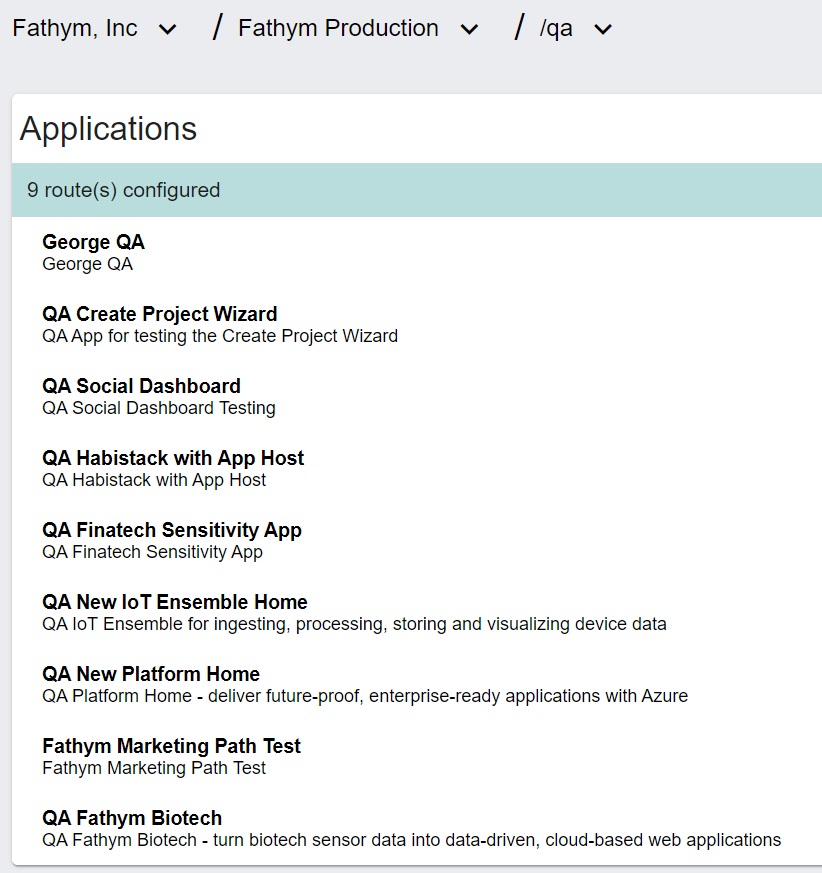
So why don’t users see Fathym’s testing? That’s easy. These QA paths are all hosted on different paths than is what is shown in production.
Each of the Fathym developers is working on different development – some on new features, some on bugs, some on new products. Each developer will be doing their work on their own feature branch (that’s a generic term for a development branch).
Once development is done, the software tester sets up a different path for the feature branch. So, for example, when George the developer gets something finished and it is ready for QA testing, Matt the tester will create a route like “/qa/george”, deploy the feature branch on this route, launch the application and test all the changes.
That testing is “quarantined” to that route and that route is not exposed on production.
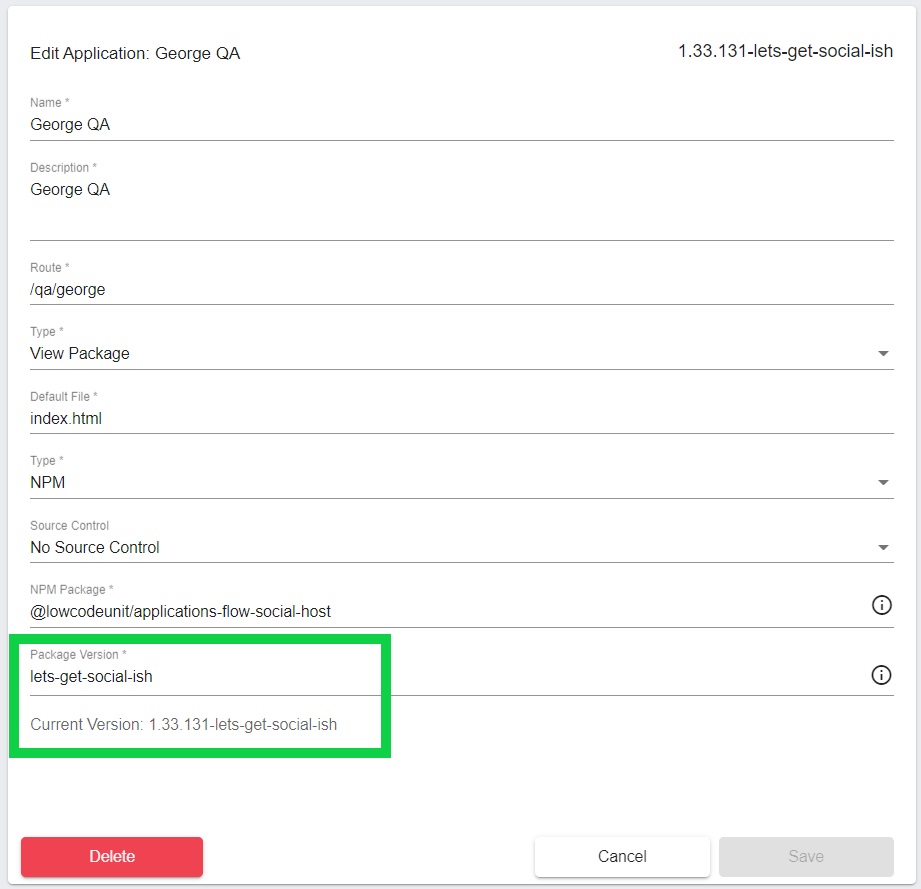
If testing finds a problem with George’s development, Matt will send the findings back to George to get fixed. George will fix them, build, unit test and create a new version. Because Matt already has the infrastructure in place to test George’s feature branch, all that is needed is to update the version. That’s done on the Edit Application page.
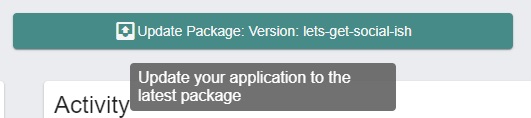
In this case, the tester would deploy the “latest” of the feature branch by clicking on the green Update Package button on that same page. Testing would take place once more.
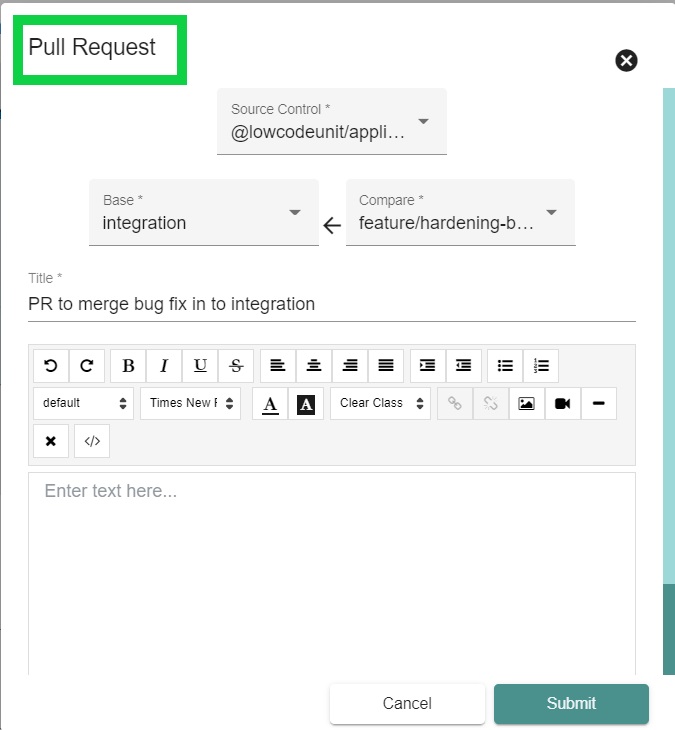
If testing all passed, Matt would tell George that it was ok to merge this feature. George would create a pull request for this action.
Activity Feed
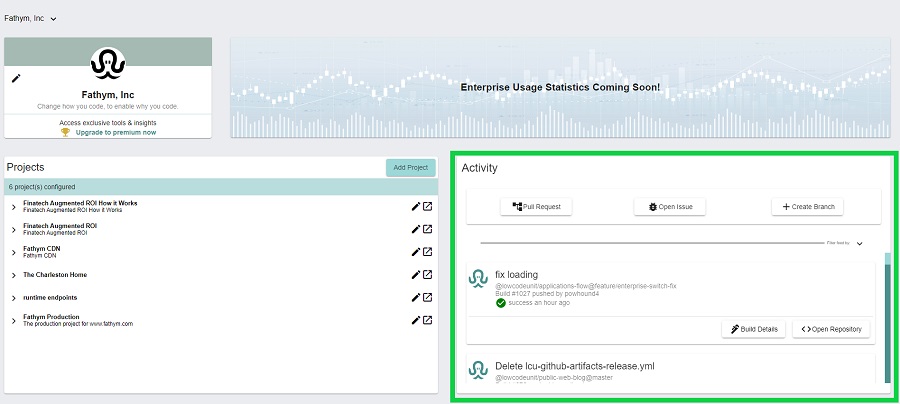
The activity feed will show on the right side of your dashboard. It is a super useful tool that helps you “see” all the activity for your projects. It’s a particularly convenient way to track all the activity across all the repositories your organization has. The feed aggregates the activity in the repos in this one location on your dashboard. This saves you from having to go to GitHub and jump around repos to see if anything is happening. It also allows you an easy way to navigate to repos related to each activity – a link to the repo is stated on each card.
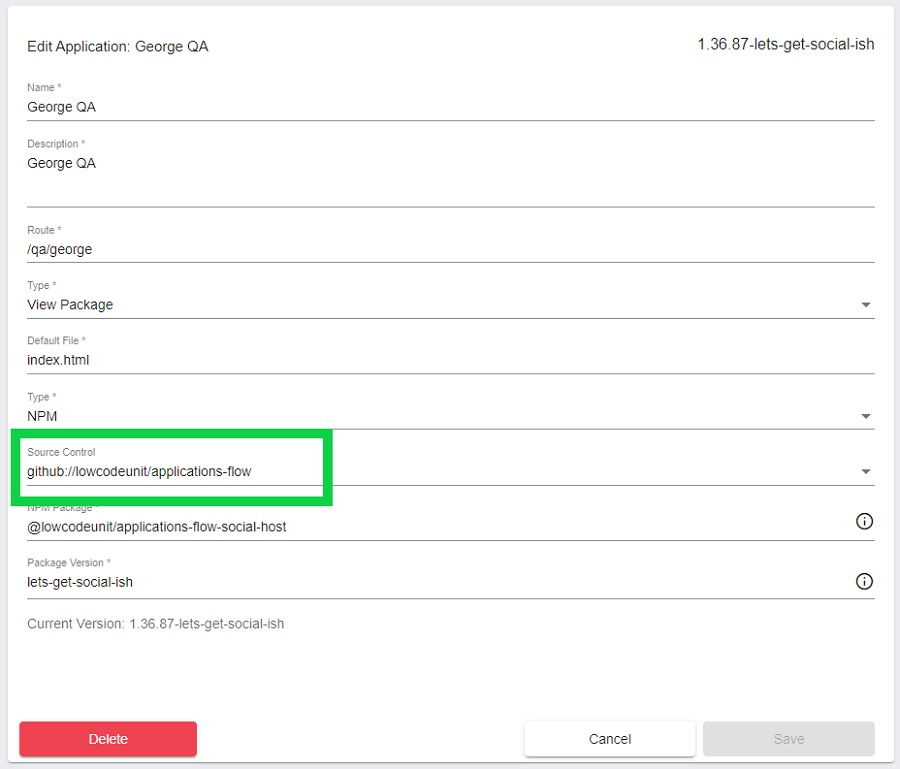
As a bonus, the activity feed is dynamic and adapts to the level you are at on your dashboard. It will list all repos on the project level. On the application level, the feed is specific for the repo the application is using. That is controlled by the Source Control field in the application settings.
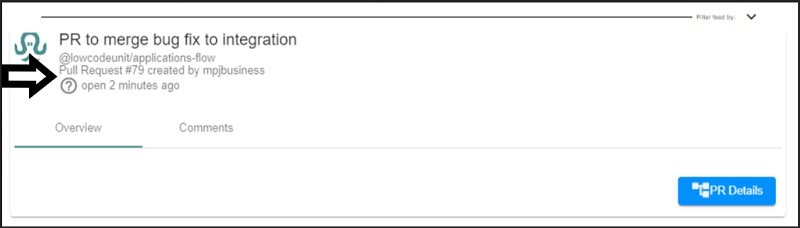
Let’s go back to the pull request that George created – the card for the PR would pop up in the Activity Feed on the dashboard, like the one pictured above.
At this point, based on the way Fathym has configured its best practice DevOps workflows, the pull request would require review by a senior developer – this would ensure that the feature is not introducing bad or poorly written code into the code base. The reviewer would not get a notification for this review, rather they would see the new PR pop into their own activity feed and click the blue “PR Details” button which would navigate them directly to the pull request in GitHub for review and approval.
Within the Activity Feed, the pull request would tell George (or whoever is viewing the dashboard) that the build is happening - this is indicated by the spinning circle on the card. If an action remains to be taken on the pull request, the question mark is shown on the card.
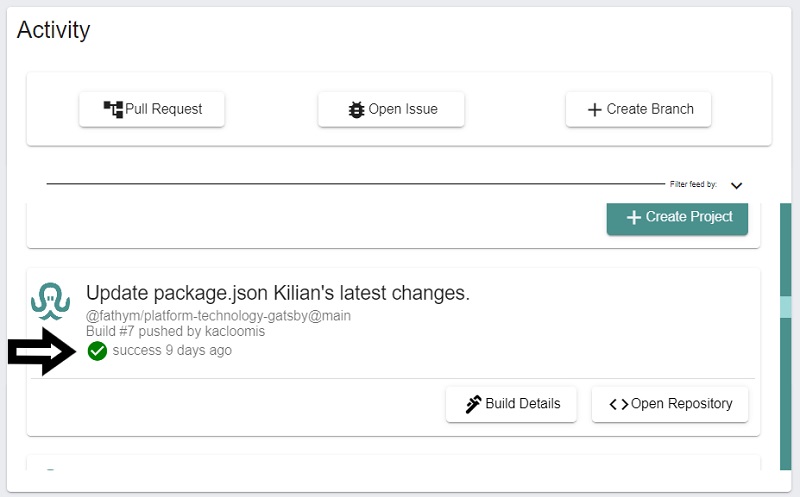
When the build is finished, the card on the activity feed would have a green check mark when it was done building successfully. Note – if the build was not successful, it would have a red X.
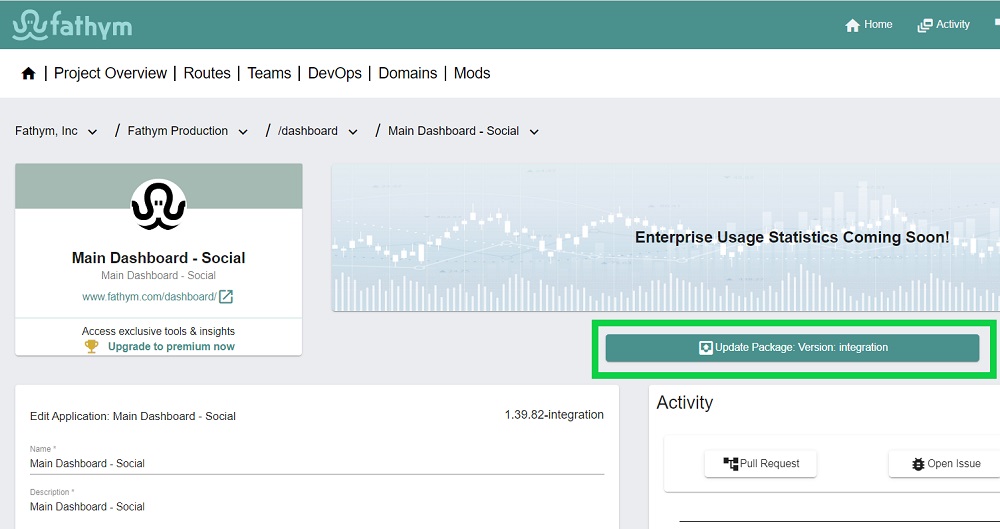
Once the request was done and the feature had been merged, Matt the tester would go to the Fathym production application, such as /dashboard, unpack the latest version of integration, which is what is deployed in production now, and the changes that George made would now be in production.
Developers Test in Production
This testing capability isn’t just for the QA department. Developers use these QA paths at times, too.
Sometimes it is difficult to test locally, or developed code looks or behaves differently when they are testing locally than when it is deployed. So, QA can set up their feature branch on one of the test paths, and the developers can go out there and understand how their code would look and behave in production. This allows the developer to be as “close” as possible to production and understand what their developed functionality will be like. This assists the developer with their unit testing and helps to ensure that their new code will not break the existing application.
Turning the Tables on QA
Fathym tests front end features and updates in production.
We do this because we created the software to do this. We faced this problem ourselves. It’s expensive to stand up multiple software environments. It’s time-consuming and resource-consuming. There is a whole orchestration of things that must take place to ensure the environments stay in sync. If they get out of sync, it can be a mess to get them back in lockstep. There is communication that must be done to ensure we know what development is in what environment. It takes a boatload of coordination to do software development and testing this way.
There is a better way to test frontends using the Fathym technology. Try this for yourself – learn more at Fathym.com.